




[SQL SERVER] - BULK INSERT AUTOMATIZADO E DINÂMICO
Sobre o Projeto
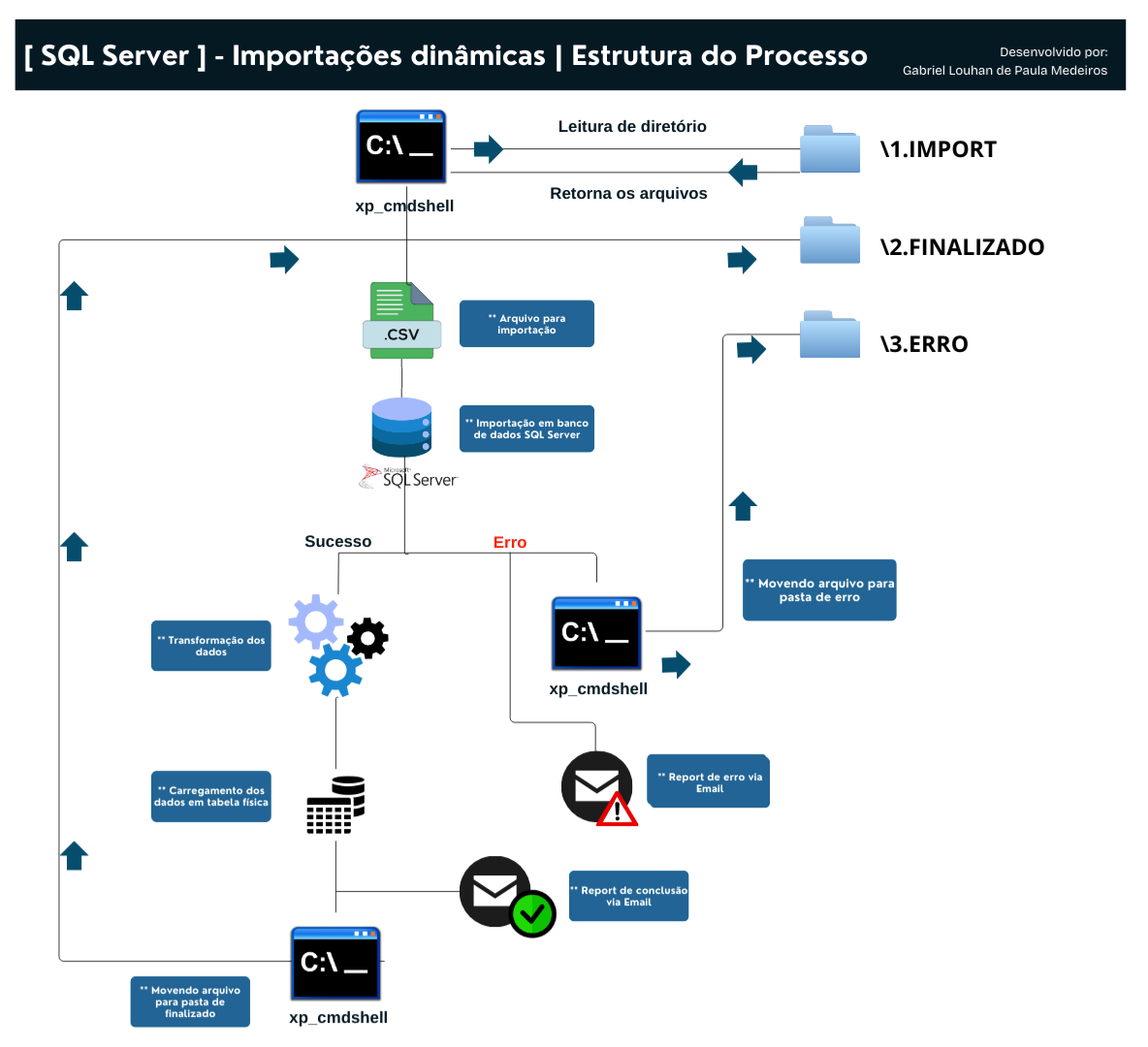
Processo automatizado desenvolvido para gerenciar a importação de arquivos via SQL Server. Ele lê um diretório específico, processa os arquivos de forma dinâmica e os insere no banco de dados, garantindo agilidade e confiabilidade.
O processo foi desenvolvido com a capacidade de lidar com possiveis erros. Envia relatorios por email sinalizando o status da execução (sucesso/falha) com informações de duração, linhas afetadas, horario que finalizou, descrição e informações de erro (caso ocorra), Alem de organizar os arquivos em diretorios de acordo com o status da execução (sucesso/erro).
Com essa automação, eliminamos a necessidade de intervenções manuais, reduzimos falhas humanas e obtemos maior eficiência.
Importante
Este projeto utiliza conceitos avançados de segurança no servidor, incluindo o uso do xp_cmdshell, que permite a execução de scripts diretamente via prompt de comando.
Foram utilizados apenas comandos básicos, como move e dir, que não comprometem a integridade ou segurança do servidor. No entanto, para fins de estudo e testes, recomenda-se a execução em ambientes controlados ou por meio de procedures que atuem como intermediárias na execução desses scripts para evitar riscos potenciais.
Benefícios do Processo
- Eficiência e Performance: Importação rápida de grandes volumes de dados.
- Automação Completa: Execução sem intervenção manual, organizando arquivos automaticamente.
- Segurança e Monitoramento: Envio de relatórios automáticos via e-mail com status de sucesso ou falha.
- Escalabilidade: Adapta-se a diferentes arquivos e pode ser executado em paralelo.
- Redução de Erros: Processo padronizado que evita falhas humanas.
Job de execução

Defini o agendamento para rodar apenas em horario comercial (08h as 18h) de segunda a sexta a cada 10min.
Arquivo csv
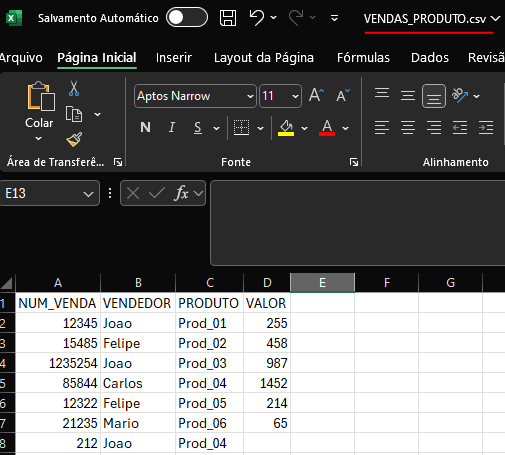
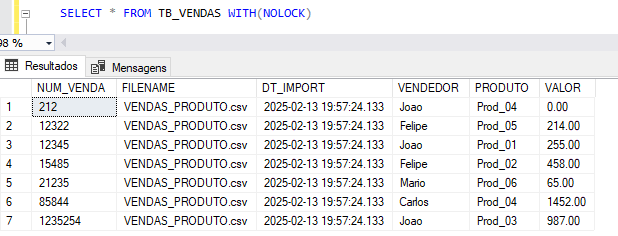
Tabela destino: TB_VENDAS
Hierarquia de diretórios conforme sua classificação

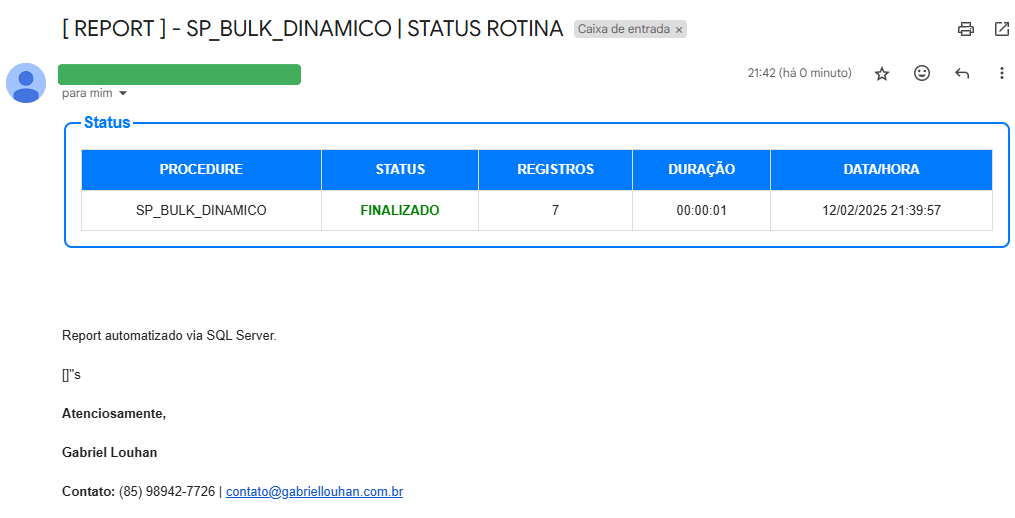
Report E-mail | Sucesso
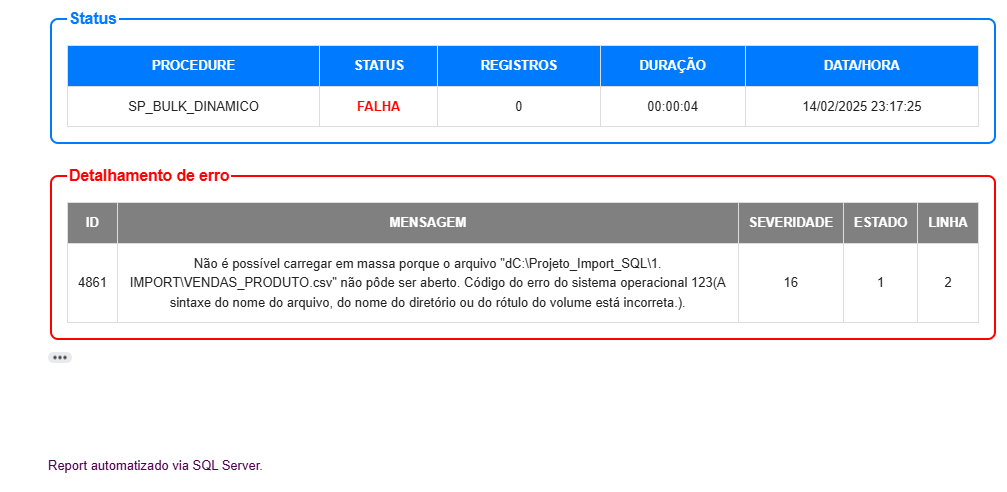
Report E-mail | Falha
Estrutura tabela TB_VENDAS
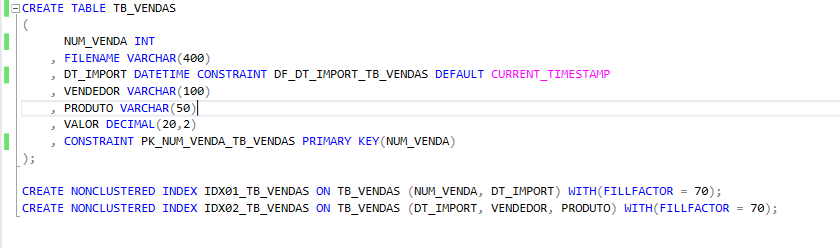
TB_VENDAS será utilizada para armazenar o resultado final da importação, já apos todas as tratativas necessárias.
A tabela contém 7 colunas, contendo duas constraints do tipo PRIMARY KEY na coluna NUM_VENDA que além de garantir a unicidade da informação, vai me ajudar em performance no momento de atualização da base quando relacionado o campo NUM_VENDA no merge ou por consultas especificas. E um campo DEFAULT em DT_IMPORT, com o objetivo de capturar o momento exato em que ocorreu a importação de forma automática após o insert.
Indices:
Os indices foram projetados para ocupar até 70% da pagina, o objetivo é reduzir a ocorrências de page splits e fragmentação.
- IDX01_TB_VENDAS: Utilizando as colunas NUM_VENDA e DT_IMPORT, esse indice visa melhorar a performance de consultas em que relacionem essas duas colunas diretamente, como por exemplo o batimento de informações levando em consideração data da importação e ID da venda..
- IDX02_TB_VENDAS: Projetado para consultas que filtrem por periodos de data, produto ou vendedor. melhorando a eficiência em análises temporais e segmentações.
Variáveis do projeto
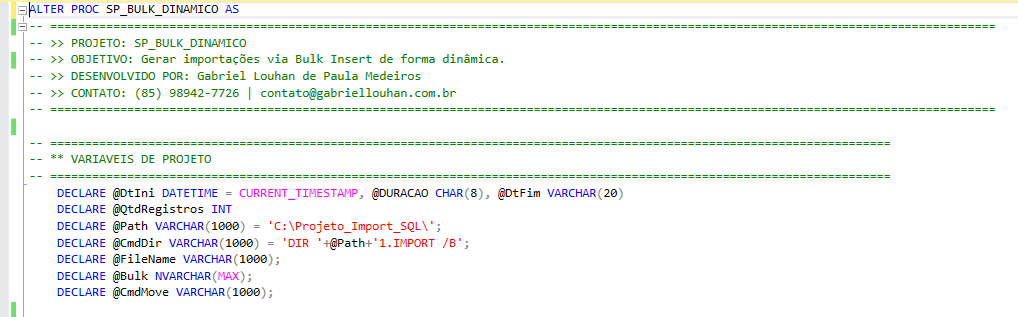
Etapa responsável pela criação das variáveis que vão armazenar algumas das informações necessárias para a execução do processo.
Dentre essas informações estão: Informações de horário e duração da execução da procedure, quantidade de registros afetados, diretórios, comandos xp_cmdshell, comandos Bulk..
Realizando a leitura do diretório \1.IMPORT
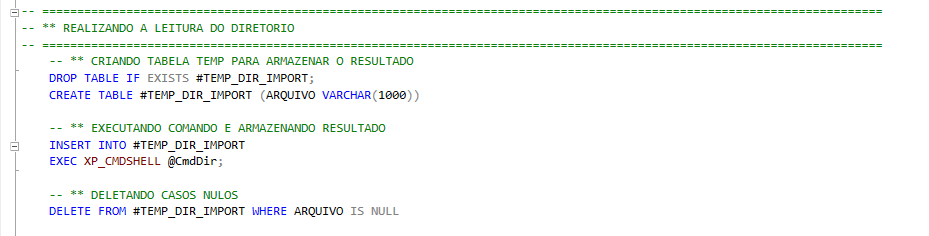
- #TEMP_DIR_IMPORT: Tabela temporaria local utilizada para armazenar o nome dos arquivos presentes no diretório "\1.IMPORT\" no momento da execução.
- @CmdDir: Variável responsável por armazenar o comando de leitura (dir) no diretorio de importação, e posteriormente executada via xp_cmdshell.
Apos a execução do comando de leitura do diretório e armazenamento dos dados em tabela temporaria, é feito a limpeza dessa base, deletando os casos nulos e mantendo apenas dados com informação de filename.
Iniciando Looping While
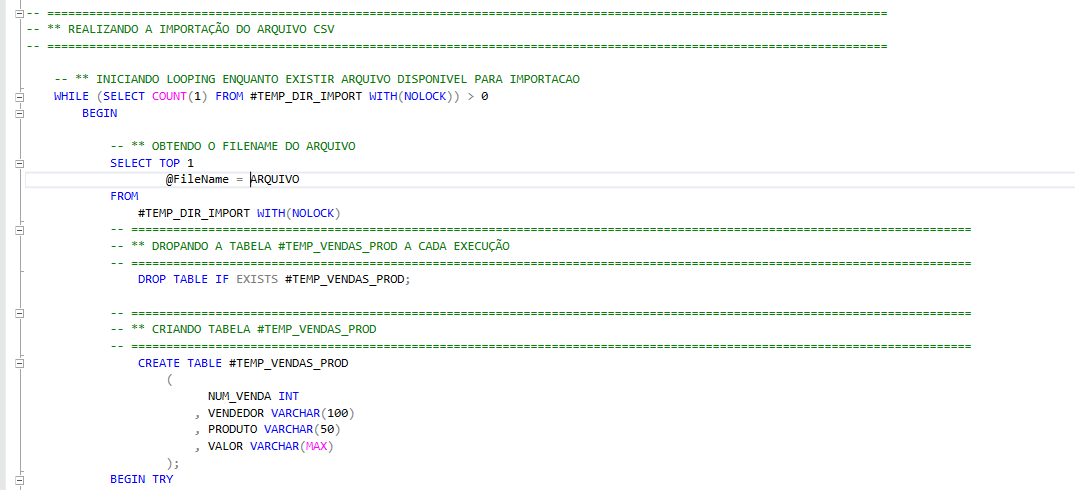
O objetivo desse Looping While é que execute as importações enquanto existir arquivos disponiveis no diretório de importação.
Essa validação é feita a partir da condição passada na estrutura de repetição "(SELECT COUNT(1) FROM #TEMP_DIR_IMPORT WITH(NOLOCK)) > 0"
Em seguida obtenho os FileNames limitando uma linha por execução e armazeno na variavel de @Filename, que posteriormente sera utilizada como parâmetro na etapa de importação.
Após isso, crio uma tabela temporaria local #TEMP_TB_VENDAS espelhando o layout de colunas da tabela destino TB_VENDAS, nessa temp deixo a coluna de "VALOR" como "VARCHAR", para posterior tratativa antes de importar como decimal em tabela fisica.
Realizando a importação e transformação dos dados

Ainda dentro do looping while, é aberto um bloco para tratativa de erros "BEGIN TRY".
Em seguida é desenhada a estrutura do bulk insert dentro da variável @Bulk, utilizando as variáveis @Path e @FileName obtidas dinamicamente dentro do while.
PARAMETROS DO BULK INSERT:
- "FIRSTROW = 2": Informo que os dados a serem obtidos estão contidos a partir da segunda linha do arquivo ( desconsiderando os cabeçalhos).
- "FIELDTERMINATOR = ';' ": Definindo o delimitador utilizado no arquivo.
- "CODPAGE = 65001": Definindo a codificação do arquivo a ser interpretado como UTF-8.
Em seguida, realizo a transformação dos dados da coluna VALOR, verifico se os dados presentes nessa coluna tem um formato numerico, para então converter em decimal.
MERGE | Atualizando tabela fisica
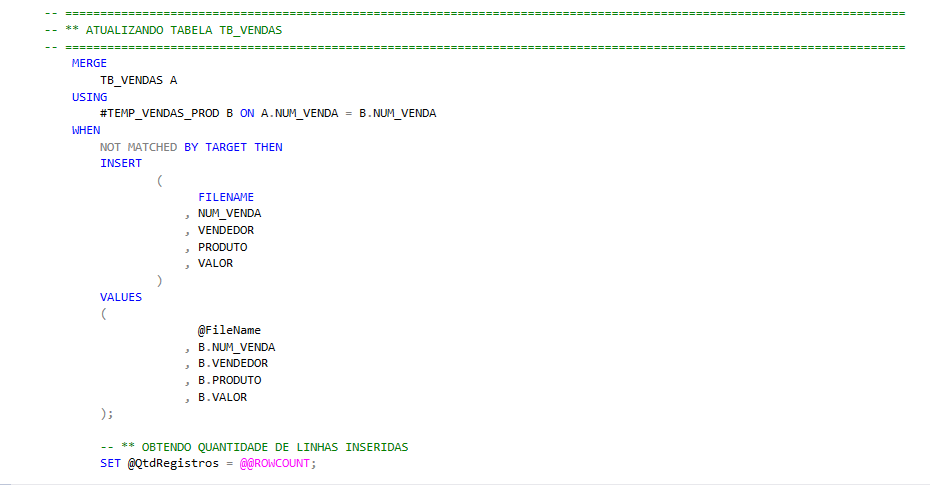
Apos todas as tratativas necessárias, agora é o momento de carregar esses dados em tabela fisica.
Utilizo o MERGE para fazer a atualização do objeto, relacionando NUM_VENDA entre os objetos e inserindo na tabela somente registros novos.
Ao finalizar a atualização, é obtido a quantidade de linhas afetadas por meio da variavel de ambiente @@ROWCOUNT e armazenado em minha variavel @QtdRegistros, para posterior uso no report de email.
Movendo arquivos e Enviando Report por email
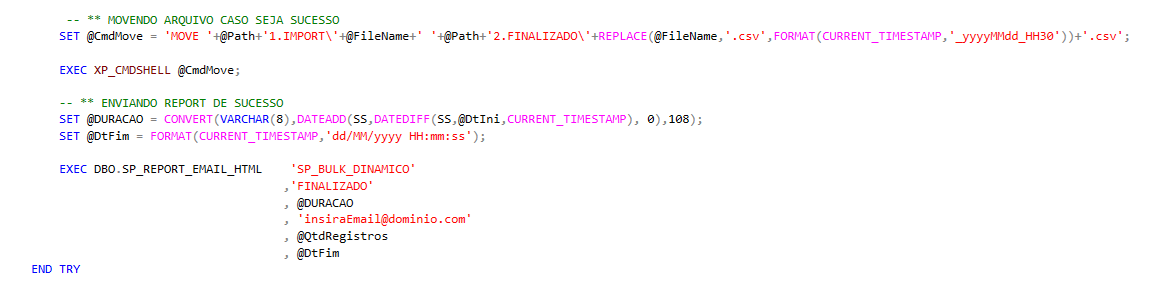
Dentro da variavel @CmdMove armazeno o comando de "mover" o arquivo entre os diretórios, com o uso das variaveis @FileName e @Path deixando esse comando dinâmico a cada execução do looping.
Além disso, também realizo uma alteração no nome do arquivo ao exportar, utilizando o comando FORMAT adiciono ao final do filename a informação de "AnoMesDia_Hora30.csv". dessa forma garanto que o arquivos recepcionados com o mesmo filename não seram substituidos ao mover de pasta.
Agora é hora de enviar um alerta por email, informando o sucesso da execução da procedure.
Faço isso utilizando uma outra procedure que desenvolvi para esta tarefa (SP_REPORT_EMAIL_HTML), na qual passo os parametros necessários e ela realiza o envio.
Detalhes da procedure SP_REPORT_EMAIL_HTML:
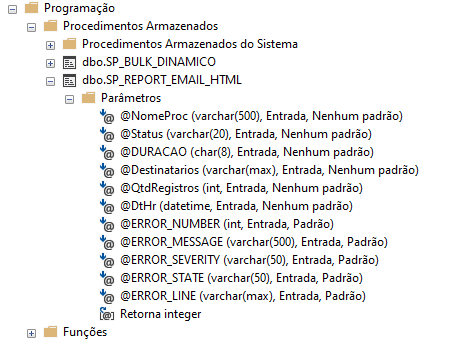
Após isso é finalizado o bloco TRY.
Tratando erros de execução

Nessa etapa é reservada para tratativa de eventuais erros na execução do processo, por meio do BEGIN CATCH.
Seguindo a mesma logica da etapa anterior, aqui o processo tem como objetivo apos identificar o erro, mover o arquivo de pasta e enviar um alerta por email.
Diretório origem: \1.IMPORT
Diretório destino: \3.ERRO
O alerta de erro é enviado por email, utilizando a procedure SP_REPORT_EMAIL_HTML repassando os devidos parametros de erro.
Finalizando processo | Controle de Looping While
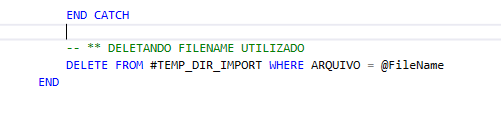
Etapa final do processo, onde realizo o delete na tabela #TEMP_DIR_IMPORT filtrando pelo @FileName utilizado, garantindo assim que o looping tenha fim ao percorrer todos os arquivos disponiveis.
Em seguida finalizo o processo.